Part 3. 내게 필요한 정보를 자동하기. 웹 크롤링
I. 크롤링을 위한 준비
1. 크롬브라우저 설치
https://www.google.com/chrome/
2. 크롬브라우저 버전확인
chrome://settings/help
3. 크롬드라이버 다운로드
- Selenium을 사용하려면, 크롬 브라우저와 호환되는 ChromeDriver가 필요
- Python의 webdriver-manager 라이브러리를 사용해 자동으로 ChromeDriver를 설치
- 필요한 라이브러리 설치 :

- ChromeDriver 설치 및 실행 코드:

4. Selenium으로 Chrome 브라우저 실행하기
- 크롬브라우져 실행 및 url 지정
- 주니퍼로 크롬브라우저 실행함


5. Selenium 주요 기능 및 활용
- 크롬브라우져 실행 및 url 지정

5-1. 요소 찾기 (By)
- Selenium은 웹 페이지의 특정 요소를 찾기 위해 `By`를 사용함.

- 주요 By 메서드
By.CLASS_NAME # 클래스명으로 요소 찾기
By.ID # ID로 요소 찾기
By.TAG_NAME # 태그 이름으로 요소 찾기
5-2. 단일 요소 가져오기
- 단일 요소 가져오기 : find_element
- 특정 조건을 만족하는 첫 번째 요소만 가져온다.
- 반환 값: 단일 요소 (Element 객체)
- element = browser.find_element(By.CLASS_NAME, "shortcut_list") # 첫 번째 요소만 반환
5-3. 여러 요소 가져오기
- 여러 요소 가져오기 : find_elements
- 특정 조건을 만족하는 모든 요소를 리스트(List) 형태로 반환한다.
- 반환 값: 요소의 리스트 (List)
- elements = browser.find_elements(By.CLASS_NAME, "shortcut_list") # 리스트 반환
5-4. 주의사항
- find_element는 해당 요소가 존재하지 않을 경우 오류를 발생시킨다.
- find_elements는 해당 요소가 없을 경우 빈 리스트를 반환한다.
6. 요소 찾기 실습
6-1. 네이버 날씨로 이동
- url 지정하여 변수 'url'에 담는다.

6-2. '현재 온도'의 요소 찾기
- 원하는 위치에서 오른쪽 클릭 한 후 '검사'클릭

6-3. 개발자창 드면 '현재 온도'의 요소가 있는 부분에 회식 부분이 선택된 것을 알 수 있다.
- 그 중 "current minus"나고 나온 부분중 "current" 부분을 나의 요소로 가져온다. (파이썬에서는 요소의 띄워쓰기는 입력에러임)

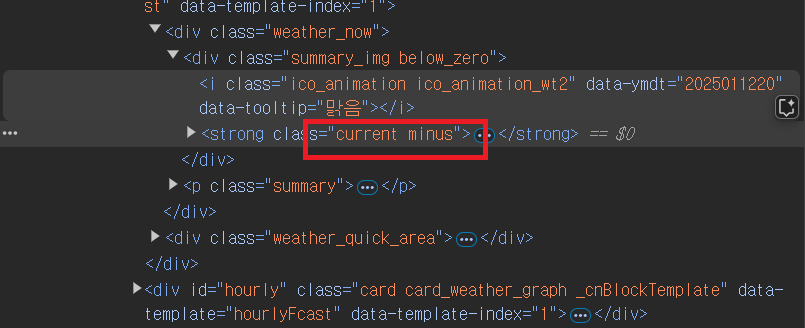
6-4. "현재 온도" 불러오기

6-5. "나의 위치", "습도, 체감온도, 풍향, 풍속"도 불러오기
- 개발자 창에서 상단 좌측의 버튼(점선으로된 사각형에 화살표 표시)을 클릭하면 원하는 요소가 강조된다.

- 거기서 "습도"를 클릭해 보면 우측창에 클릭한 부분이 표시된다.

- 그 상단 class를 선택하면 습도, 체감, 풍향이 모두 표시 되었다.
- 원하는 요소는 "weather_table"이고, 이 요소를 불러온다.



- 원하는 요소를 불러왔다.
▶ 위와 같이 원하는 '단일 요소'를 불러 왔음
▶ '다중 요소' 불러오기는 "II. 데이터 수집" 참고
II. 데이터 수집
A. 네이버 부동산을 활용한 부동산 매물 수집
1. 크롬브라우저 열
from selenium import webdriver # 셀레늄에서 웹드라이버 가져오기
browser = webdriver.Chrome() # 크롬브라우저를 열고 그 크롬브라우저를 변수 browser에 담아준다.
2. 네이버 부동산 창 열기
url = 'https://new.land.naver.com/complexes/728?ms=37.525563,127.020506,17&a=APT:ABYG:JGC:PRE&e=RETAIL'
browser.get(url) # 브라우저로 url을 가져옴 # 압구정동 현대 미성아파트의 정보를 가져오고자 함.
▶ 멀티데이터 가져오기
- 일단 1개를 가져오게 되면, 반복문을 통해 무한개를 가져올 수 있다.
3. 일단 단일 요소 가져오기
from selenium.webdriver.common.by import By # 셀레니움을 통해 요소를 가져온다. # from. 오타주의
browser.find_element(By.CLASS_NAME, "item_title").text # 동정보
browser.find_element(By.CLASS_NAME, "price_line").text # 가격정보
browser.find_element(By.CLASS_NAME, "info_area").text.split(", ") # 매몰정보 # .text는 요소정보를 텍스트로 반환시킴
>>> ['아파트112B/105m²', '8/14층', '남향\n체크 34P 리바트 특올수리 첫입주I 장기거주I 신사중', '현대고 초인접']
▶ N개의 정보를 가져오려고 한다.
- (1) 정보가 모두 담겨있는 컨테이너를 찾는다.
- (2) 해당클레스를 모두 가져와줘! => find_element (X), find_elements (O)
- find_element => WebElement.text
- find_elements => List[]
=> ["element1", "element2", "element3"] # elements와 같이 여러개 요소들이 불러진(리스트로 여러개 반환된) 이후에
=> "element1".text # element 해서 하나의 요소에서 하나의 텍스트 값을 반환 시켜야 한다....
4. 컨테이너 찾기
▶ 컨테이너 찾는법 :
- (1) 브라우저 검사창에서 상단 왼쪽 버튼 눌러서, 매물 각각의 매물 창에서 첫번째 매물창의 전체를 선택하는 부분을 클릭한다.

- (2) 그 부분의 화살표를 눌러 접어보면, 매물단위 클래스가 눈에 보일 것이다.
하나씩 하나씩 묶음 매물 단위가 하나의 '컨테이너' 이다.

- (3) 매물창에서 아래로 스크롤을 계속하게 되면, 처음 20개에서, 40개, 60개...씩 계속 늘어나게 된다. (동적로딩)
컨테이너의 요소 이름 ' item '을 찾음.

5. 컨테이너 요소 불러오기
browser.find_elements(By.CLASS_NAME, "item") # 매물들을 List화된 자료로 불러옴.
6. 컨테이너 변수 선언 및 요소를 리스트에 담
containers = browser.find_elements(By.CLASS_NAME, "item") # 리스트를 컨테이너 변수에 담는다.
print(containers)
7. 매물정보 개수 확인하기
len(containers) # 스크롤을 할수록 매물 개수가 늘어난다.
>>>80 # 데이터 개수가 늘릴려면 브라우저 창 매물부분에서 계속해서 스크롤을 돌려 아래 로 내린 후,
' browser.find_elements(By.CLASS_NAME, "item") ' 부분 부터 다시 (Kernel) running 해와야 한다.
8. 최종 불러온 요소정보를 우리가 원하는 데이터 값으로 저장하기.
data = [ ] # 최종 값을 담을 변수 선언함.
for elem in containers:
try:
동정보 = elem.find_element(By.CLASS_NAME, "item_title").text # 여러개의 컨테이너 중 값이 없는 것이 있을 수도 있다..
가격정보 = elem.find_element(By.CLASS_NAME, "price_line").text
매물정보 = elem.find_element(By.CLASS_NAME, "info_area").text.split(', ')
평수 = 매물정보[0] # Shift + Alt + 화살표 밑으로 ===> 행 카피해서 내리기
층수 = 매물정보[1]
향 = 매물정보[2].split('\n')[0]
기타 = 매물정보[2].split('\n')[1:]
print(동정보, 가격정보, 평수, 층수, 향, 기타)
data.append({ # 엑셀에서 하나의 행 데이터를 만들것이기 때문에 중괄호{} 사용한다. # 딕셔너리 타입임.
'동정보':동정보,
'가격정보':가격정보,
'평수':평수,
'층수':층수,
'향':향,
'기타':기타,
})
except: # 그래서 예외조항 만들어서 통과 시킨다.
pass
9. 최종 데이터를 csv파일 형태로 만들어서 저장하기
import pandas as pd
df = pd.DataFrame(data) #DataFrame은 2차원데이터임. # csv파일 형태로 만들기
df.to_csv("_네이버부동산_미성아파트매물정보.csv", encoding='utf-8-sig')
▶ 최종 데이터를 csv파일로 저장완료됨.
'데이터 분석 (DA)' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 9주차 (DA_MySQL) (0) | 2025.02.14 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 8주차 (DA_MySQL) (0) | 2025.02.06 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 3주차 (DA_Python) (0) | 2025.01.04 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 2주차 (DA_Statistics) (2) | 2024.12.29 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 1주차 (DA_Excel, Statistics) (2) | 2024.12.22 |



