(복습)
DML : 테이블내 DATA
- C(INSERT INTO)R(SELECT FROM)U(UPDATE SET + LIMIT)D(DELECT FROM)
DDL : DATABASE, TABLE
- C(CREATE)R(SHOW,DESC)U(ALTER)D(DROP)
DCL, TCL, DQL
DML : READ
SELECT : column : AS (alias)
FROM : table name
WHERE : condition : Operator (산술,비교,논리(AND(둘다만족),OR(둘중하나만족)))
ORDER BY : sort : ASC, DESC
LIMIT : limit : num1(limit) : num1(skip), num2(limit)
우선순위
- 연산자 우선순위 : 산술 > 비교 > 논리
- 구문실행 우선순위(실행계획) : FROM > WHERE > SELECT > ORDER BY > LIMIT
DDL : CREATE
테이블 생성 : 컬럼명, 테이터타입, 제약조건
데이터 타입 :
- 숫자 : NUMBER : INT, FLOAT, DOUBLE
- 문자 : STRING : CHAR, VARCHAR, TEXT
- 날짜 : DATE : DATETIME, TIMESTAMP
제약조건 :
- NOT NULL, UNIQUE, PRIMARY KEY(AUTO_INCREMENT), DEFAULT, FOREGIN KEY
데이터베이스 모델링 : EER다이어그램
- 모델링 절차 : 개념적모델링 > 논리적모델링 > 물리적모델링
DDL : READ : SHOW, DESC
DDL : UPDATE : ALTER : ADD, MODIFY COLUMN, DROP
DDL : DELETE : DROP : TRUNCATE(데이터초기화)
DML : UPDATE : UPDATE SET WHERE LIMIT
DML : DELETE : DELETE FROM WHERE LIMIT
FUNCTIONS (함수)
단일행함수 : 함수의 기능이 하나의 데이터에 적용
- CEIL(올림,자릿수설정못함), ROUNT(버림,자릿수설정함), TRUNCATE(반올림,반듯이자릿수설정해야함),
COMCAT(컬럼과 컬럼데이터 연결하기), DATE_FORMAT
다중행함수 : 함수의 기능이 여러개의 데이터에 적용
- COUNT, SUM, AVG, MIN, MAX, VARIANCE, DISTINCT...
CONDITION (조건문)
조건에 따라 출력되는 데이터를 다르게 할때
- IF : 조건 1개
- CASE WHEN THEN ELSE IF : 조건 2개 이상
- IFNULL : 결측데이터 처리
결측데이터 처리
- 수치형데이터 : 평균, 중앙값을 사용함
- 범주형데이터 : 최빈값을 사용함
범주형 데이터 처리
- 더미변수화 : 원핫인코딩 : 카테고리의 순서가 없을때 사용함 (ex:남성, 여성)
- 매핑 : 카테고리의 순서가 있을때 사용함 (숫자 형태로 변경 ex:승선위치 S=1, Q=2, C=3))
- 카테고리 임베딩 : 카테고리와 관련된 수치형 데이터로 변환 (ex:각 승선위치에 대한 인구수)
GROUP BY
- 데이터를 그룹핑하여 출력
- 특정컬럼(중복결합), 다른컬럼(결합함수결합)
(예제)
1) 대륙별 총인구수 출력
조건1 특정컬럼(continent), 다른컬럼(population:SUM())
조건2 대륙의 총인구수가 7억 이상인 데이터 출력
USE world;
SELECT continent, SUM(population) AS populations
FROM country
GROUP BY continent
HAVING SUM(population) >= 70000 * 10000;
2) 년월별 총 매출 데이터 출력 (실무에서 KPI (성과지표) 사용하는 방법임)
USE sakila;
SELECT payment_date, amount
FROM payment;
SELECT DATE_FORMAT(payment_date, '%Y-%m') AS monthly
, SUM(amount) AS total_amount
FROM payment
GROUP BY DATE_FORMAT(payment_date, '%Y-%m');
쿼리 실행순서
- FROM > JOIN > WHERE > GROUP BY > HAVING > SELECT > ORDER BY > LIMIT
스텝별 년월 총 매출 출력
SELECT staff_id, DATE_FORMAT(payment_date, '%Y-%m') AS monthly
, SUM(amount) AS total_amount
FROM payment
GROUP BY staff_id, monthly
# GROUP BY staff_id, DATE_FORMAT(payment_date, '%Y-%m');
# 원래는 이렇게 쓰는것이 좋다. 오라클에서는 이렇게 써야함.
# 쿼리실행우순순위에 의해 셀렉트에서 선언한것은 가장나중에 실행됨으로..
ORDER BY monthly, staff_id;
UNION
- 쿼리 실행 결과를 결합 사용
- 중복 데이터를 제거(결합)해 주는 기능
- 중복 제거를 안 하고 싶을때 : UNION ALL
USE world;
DROP TABLE IF EXISTS user;
CREATE TABLE user1(
addr VARCHAR(10)
);
CREATE TABLE user2(
addr VARCHAR(10)
);
INSERT INTO user1
VALUES ('seoul'), ('pusan'), ('incheon');
INSERT INTO user2
VALUES ('pusan'), ('incheon'), ('daegu');
SELECT * FROM user1
UNION
SELECT * FROM user2;
SELECT * FROM user1
UNION ALL
SELECT * FROM user2;mysql 버전별로 order by 사용 안됨
(연습문제)
county테이블에서 아시아와 아프리카의 총 인구수와 총 GNP를 2개의 ROW 출력
출력컬럼 : continent, total_population, totla_gnp
다중행 함수만 사용해도 됨
USE world;
SELECT * FROM country;
SELECT continent, SUM(population) AS total_population, SUM(gnp) AS total_gnp
FROM country
WHERE continent = 'Asia'
UNION
SELECT continent, SUM(population) AS total_population, SUM(gnp) AS total_gnp
FROM country
WHERE continent = 'Africa';
JOIN
- 두개의 테이블 결합하여 데이터를 출력하는 문법
- 두개의 테이블에 있는 컬럼을 한번에 출력하고 싶일 때 사용
예시) country(국가코드, 국가이름) + city(국가코드, 도시이름) = 국가코드, 국가이름, 도시이름
조인의 종류 (총6가지)
- INNER, LEFT, RIGHT, OUTER, CROSS, SELF (LEFT와 RIGHT 테이블의 기준은 테이블이 만들어진 시간순서임)
그중 INNER, LEFT 가장 많이 사용함
- 이커머스에서 1고객 3번구매, 2고객 4번구매, 3고객 0번구매시 유저테이블과 페이먼트테이블 결합시 left조인을 해야
3고객이 같이 합쳐짐.
3고객의 페이번트 값인 null 값을 IFNULL을 이용하여 0값으로 넣어어 사용하는 경우가 많다.
- 실무에서 조인할 때 주의를 해야 한다.....★★★
- 조인은 각 테이블간의 모든 경우의 수를 조합한 이후에 INNER, LEFT등 조인 명령을 사용하여 값을 필터링 하는 개념임.
- 유저 2000만명, 댓글 3억개 일경우 경우의 수를 만들때 엄청난 에너지가 소모된다.
조인 테스트를 위한 데이터베이스 생성
DROP DATABASE IF EXISTS jbda;
CREATE DATABASE jbda;
USE jbda;
CREATE TABLE user(
ui INT
, un VARCHAR(20)
);
CREATE TABLE addr(
ui INT
, an VARCHAR(20)
);
INSERT INTO user
VALUES (1, 'A'), (2, 'B'), (3, 'C');
SELECT * FROM user;
INSERT INTO addr
VALUE (1, 'S'), (2, 'P'), (4, 'I'), (5, 'S');
SELECT * FROM addr;

CROSS JOIN
SELECT *
FROM user # 가장먼저 만들어진 테이블
CROSS JOIN addr; # CROSS 글자 생략가능
SELECT user.ui, user.un, addr.an
FROM user # 가장먼저 만들어진 테이블
CROSS JOIN addr; # CROSS 글자 생략가능
INNER JOIN
SELECT *
FROM user # 가장먼저 만들어진 테이블
INNER JOIN addr # INNER 글자 생략가능
ON user.ui = addr.ui;
SELECT user.ui, user.un, addr.an
FROM user # 가장먼저 만들어진 테이블
INNER JOIN addr # INNER 글자 생략가능
ON user.ui = addr.ui;
LEFT JOIN
SELECT user.ui, user.un, addr.an
FROM user # 가장먼저 만들어진 테이블
LEFT JOIN addr
ON user.ui = addr.ui;
RIGHT JOIN
SELECT addr.ui, user.un, addr.an # right의 경우에는 오른쪽 유저아이디를 셀렉트해줘야 한다.
FROM user
RIGHT JOIN addr
ON user.ui = addr.ui;
SELECT *
FROM user, addr
WHERE user.ui = addr.ui;
테이블 3개 이상을 조인할 경우에는
SELECT *
FROM A
JOIN B
ON
JOIN C
ON
JOIN D
ON;
- 기본 문법대로 하게 되면 이렇게 적어야 하는데,
SELECT *
FROM A, B, C, D
WHERE user.ui = addr.ui;
이렇게 작성 하면 훨씬 가독성 좋고 깔끔하게 작성됨.
OUTER JOIN
- mysql에서는 outer조인 명령이 없어서 union 방식을 이용해서 사용한다. (오라클에서는 지원함)
- 일단 LEFT 조인과 RIGHT 조인 을 유니온으로 합쳐준다. (중복은 제거함)
SELECT user.ui, user.un, addr.an
FROM user # 가장먼저 만들어진 테이블
LEFT JOIN addr
ON user.ui = addr.ui
UNION
SELECT addr.ui, user.un, addr.an # right의 경우에는 오른쪽 유저아이디를 셀렉트해줘야 한다.
FROM user
RIGHT JOIN addr
ON user.ui = addr.ui;
SELF JOIN
- user 테이블과 user 테이블을 조인할 수 있슴
- SELF 조인만 명시해 주면 됨.
(연습문제1)
USE world;
SELECT code, name, population
FROM country;
SELECT countrycode, name, population
FROM city;
- 조건1 : 국가코드, 국가이름, 도시이름, 국가인구수, 도시인구수 출력
- 조건2 : 도시화율(도시인구수/국가인구수)
- 조건3 : 100만명 이상의 도시인구가 있는 데이터를 도시화율 내림차순으로 출력
- 조건4 : 도시화율이 높은 6~10위까지 도시들을 내림차순으로 출력하라
SELECT country.code
, country.name AS country_name
, city.name AS city_name
, country.population AS country_popu
, city.population AS city_popu
, ROUND(city.population / country.population * 100, 2) AS ratio # <== 조건2 추가
FROM country
JOIN city
ON country.code = city.countrycode
HAVING city.population >= 100 * 10000 # <== 조건3 추가
ORDER BY ratio DESC
LIMIT 5, 5; # <== 조건4 추가
(연습문제2)
SELECT countrycode, language, percentage
FROM countrylanguage;
SELECT code, name, population
FROM country;
# 국가코드, 국가이름, 언어종류, 국가인구수, 언어사용률
, 국가언어사용인구수(100명단위 : leng_pop) 퍼센트 * 인구수
SELECT country.code
, country.name
, countrylanguage.language
, countrylanguage.percentage
, country.population
, ROUND(countrylanguage.percentage * country.population / 100 ,-2) AS leng_pop
FROM country
JOIN countrylanguage
ON country.code = countrylanguage.countrycode
ORDER BY countrylanguage.percentage DESC;
(연습문제3)
USE sakila;
SELECT staff_id, amount
FROM payment;
SELECT staff_id, first_name, last_name
FROM staff;
스탭아이디, 전체이름, 매출 출력
SELECT payment.staff_id
# , staff.first_name <== 한방에 다 풀려고 하지말고, 순차적으로 차근차근 작성하면서 실행하라.
# , staff.last_name <== 한방에 다 풀려고 하지말고, 순차적으로 차근차근 작성하면서 실행하라.
, CONCAT(staff.first_name, ' ', staff.last_name)
, payment.amount
FROM payment # <== LEFT 테이블이 됨
JOIN staff # <== RIGHT 테이블이 됨
ON payment.staff_id = staff.staff_id
ORDER BY payment.amount DESC;
3개 테이블 JOIN하기
USE world;
SELECT *
FROM country; # 컬럼확인 : code, name population
SELECT *
FROM city; # 컬럼확인 : countrycode, language, percentage
SELECT *
FROM countrylanguage; # 컬럼확인 : countrycode, language, percent
국가코드, 국가이름, 도시이름, 사용언어, 도시인구수, 언어사용비율, 도시언어사용인구수
- country city countrylanguage
SELECT country.code
, country.name
, city.name
, countrylanguage.language
, city.population
, countrylanguage.percentage
, ROUND(city.population * countrylanguage.percentage / 100, -2) AS lang_pop
FROM country
JOIN city
ON country.code = city.countrycode
JOIN countrylanguage
ON country.code = countrylanguage.countrycode;
(JOIN ON JOIN ON 을) FROM 절에서 JOIN 하기
SELECT country.code
, city.name
, countrylanguage.language
, city.population
, countrylanguage.percentage
, ROUND(city.population * countrylanguage.percentage / 100, -2) AS lang_pop
FROM country, city, countrylanguage
WHERE country.code = city.countrycode
AND country.code = countrylanguage.countrycode;
SUB QUERY : 서브쿼리
쿼리 안에 쿼리를 작성하는 방법
사용가능 구문 : SELECT, FROM(JOIN), WHERE(HAVING)
SELECT 구문
전세계의 총국가수, 총도시수, 총언어종류수를 1개의 로우로 출력 (가로방향 출력시)
SELECT (SELECT COUNT(*) FROM country) AS country_count
, (SELECT COUNT(*) FROM city) AS city_count
, (SELECT COUNT(DISTINCT(language)) FROM countrylanguage) AS countrylanguage_count
FROM dual;
어떤 쿼리가 좋은가??? ★★★★★★★
===> 서브쿼리를 사용하여 필터링을 먼저 해준다음에 조인을 해주는 것이좋다.
===> 효율적인 데이터 운영을 위해 필터링을 먼저 진행해 주면 조인 계산할 자료들이 현저히 줄어든다....
FROM 구문
도시인구수 800만이상인 국가코드, 국가이름, 도시이름, 도시인구수 출력 (JOIN, HAVING 사용)
1) 일반적 쿼리 사용시
실행계획 : JOIN > FILTERING(HAVING) ===> JOIN(239*4096) > FILTERING(HAVING:10)
SELECT country.code, country.name, city.name, city.population
FROM country
JOIN city
ON country.code = city.countrycode
# WHERE country.code = city.countrycode
# 이렇게 사용해도 결과값은 나오지만, 표준 방식은 아니다. 오라클에서는 실행안됨.
HAVING city.population >= 800 * 10000;
2) 서브쿼리사용시
실행계획 : FILTERING(WHERE) > JOIN ===> FILTERING(WHERE:10) > JOIN(239*10)
SELECT country.code, country.name, city.name, city.population
FROM country
JOIN (SELECT *
FROM city
WHERE population >= 800 * 10000) AS city
ON country.code = city.countrycode;
JOIN ON 다음에는 어떤 컬럼에서 오는지 명시해 주는 것이 좋다.

WHERE 구문
한국보다 인구수가 많은 국가의 국가코드, 국가이름, 인구수 출력하기
풀이1. 한국의 인구수 출력
SELECT population FROM country WHERE code = 'KOR';
풀이2. 한국의 인구수 보다 많은 데이터 출력
1) 일반적 쿼리 사용시
SELECT code, name, population
FROM country
WHERE population > 46844000;근데 인구수는 유동적이다.
===> "이런코드는 유지보수가 좋지 않은 코드다." 라고한다. (인구수가 바뀔때 마다 업데이트 해줘야 함.)

이것을 좋게 만들려면, 서브쿼리 사용하는 코드로 바꾼다.
2) 서브쿼리 사용시
SELECT code, name, population
FROM country
WHERE population > (
SELECT population FROM country WHERE code = 'KOR'
);
INDEX
데이터베이스에서 빠른 검색속도를 제공해주는 문법
컬럼을 기준으로 설정
장점 : READ 빨라짐
단점 : CREATE, UPDATE, DELETE 느려짐 : 저장공간을 10%정도 더 사용
사용팀 : WHERE 구문에서 자주 사용되는 컬럼을 지정
종류 : 클러스터형(데이터정렬목적:PRIMARY KEY), 보조(일부데이터를 INDEX사용:속도가 빨라짐)
구조 : 트리구조 => 비트리알고리즘을 사용함
CREATE DATABASE mybda;
USE mybda;
# Server > Data import
SELECT COUNT(*) FROM salaries;
SELECT * FROM salaries;
인덱스 목록 확인 : 0.000초 걸림
SHOW INDEX FROM salaries;

인덱스 사용 X : 0.656초 걸림
SELECT * FROM salaries WHERE to_date < '1986-01-01';

# 인덱스 추가 : 6.297초 걸림
CREATE INDEX tdate ON salaries(to_date);
SHOW INDEX FROM salaries;


# 인덱스 사용 O : 0.015초 걸림
SELECT * FROM salaries WHERE to_date < '1986-01-01';

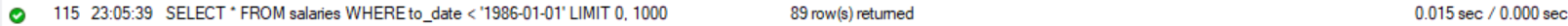
# 인덱스 삭제
DROP INDEX tdate ON salaries;
SHOW INDEX FROM salaries;

SUB QUERY
- 쿼리 안에 쿼리 작성하는 문법
- SELECT, FROM(JOIN), WHERE(HAVING)
USE world;
SELECT survived, name, TRUNCATE(age, -1) AS ages
FROM titanic
WHERE ages >= 40;
# ===> 이렇게 사용은 불가능. 쿼리실행순서가 잘못됨
# ===> 아래 서브 쿼리를 이용하면 가능함
쿼리의 실행순서를 변경하고 싶을때
쿼리실행 결과데이터를 다시 쿼리를 사용하여 결과를 출력하고 싶을때
SELECT sub.survived, sub.name, sub.ages
FROM (
SELECT survived, name, TRUNCATE(age, -1) AS ages
FROM titanic
) AS sub
WHERE ages >= 40;
DDL : CREATE
TABLE : 컬럼이름, 데이터타입, 제약조건
데이터타입
- 숫자(INT, FLOAT, DOUBLE), 문자(CHAR, VARCHAR, TEXT), 날짜(DATETIME, TIMESTAMP)
제약조건
- NOT NULL, UNIQUE, PRIMARY KEY (AUTO_INCREMENT), DEFAULT(CURRENT_TIMESTAMP)
- FORGIEN KEY : 외래키
- 테이블사이에 관계형성
- 데이터의 무결성 (원하지 않는 데이터가 저장 x) 지켜줌
- ON UPDATE, ON DELETE
- CASCADE, SET NULL, NO ACTION, SET DEFAULT, RESTRICT
DDL UPDATE : ALTER : ADD, MODIFY COLUMN, DROP
DDL DELETE : DROP
DML CREATE : INSERT INTO table VALUES (value) : INSERT INTO table SELECT FROM
DML UPDATE : UPDATE SET WHERE LIMIT
DML DELETE : DELETE FROM WHERE LIMIT
FUNCTION : 미리 만들어진 특별한 기능을 사용하는 문법
단일행 함수 : 하나의 데이터에 특별한 기능이 적용됨
- CEIL(), ROUND(), TRANCATE(), CONCAT(), DATE_FORMAT()
다중행 함수 : 여러개의 데이터에 특별한 기능이 적용됨
- SUM(), AVG(), MIN(), MAX(), COUNT(), VARIANCE(), POW()...
데이터베이스 모델링 : 스키마를 디자인 하는 방법
모델링 절차 : 개념적모델링 > 논리적모델링 > 물리적모델링 : EER다이어그램
INDEX : 데이터를 읽어올때 속도를 빠르게 하기 위한 문법
장점 : READ 속도가 빨라짐
단점 : CREATE, UPDATE, DELETE 속도가 느려짐 : 저장공간을 10% 정도 더 사용됨
데이터의 컬럼단위를 설정 가능(여러개의 컬럼설정 가능)
VIEW
가상의 테이블로 실제 데이터를 저장하지 않음
사용이유 : 복잡한 쿼리를 단순하게 변경하기 위해
특징 : 직접적으로 데이터의 수정, 변경이 불가능
800만이상 도시인구를 갖는 도시의 국가코드, 국가이름, 도시인구, 도시인구수 출력
SELECT country.code, country.name, city.name, city.population
FROM country
JOIN (SELECT countrycode, name, population
FROM city
WHERE population >= 800 * 10000) AS city
ON country.code = city.countrycode;
# 뷰생성
CREATE VIEW city_800 AS
SELECT countrycode, name, population
FROM city
WHERE population >= 800 * 10000;

# 뷰사용
SELECT * FROM city_800;
# 뷰사용
SELECT country.code, country.name, city.name, city.population
FROM country
JOIN city_800 AS city
ON country.code = city.countrycode;
TRIGGER
- 특정 테이블의 쿼리실행을 감시하고 있다가 설정한 쿼리가 실행되면
- 미리 작성해 놓은 쿼리가 자동으로 실행되도록하는 문법임.
- 데이터를 1차적으로 백업하는 효과가 있다
- 특정테이블(city), 감시쿼리(DELETE), 미리작성(INSERT)
자동 : INSERT INTO backup VALUES (data..)
수동 : DELETE FROM city WHERE population > 10000;
TRIGGER 작성방법(쿼리)
DELEMITER $$
CREATE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT | UPDATE | DELETE}
ON table_name FOR EACH ROW
BEGIN
trigger query;
END;
$$
DELIMITER # 쿼리의 끝을 나타내는 문자를 변경할 때 사용함.
CREATE DATABASE trbda;
USE trbda;
CREATE TABLE chat(
chat_id INT PRIMARY KEY AUTO_INCREMENT
, msg VARCHAR(100) NOT NULL
);
CREATE TABLE chat_bak(
chat_bak_id INT PRIMARY KEY AUTO_INCREMENT
, chat_id INT UNIQUE NOT NULL
, msg VARCHAR(100) NOT NULL
, bak_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
TRIGGER설정
- CTRL + T 해서 새창에서 딜리미터를 작성해준다.
데이터 삭제전에 백업하는 트리거 생성시
DELIMITER $$
CREATE TRIGGER chat_bak_tr
BEFORE DELETE ON chat
FOR EACH ROW BEGIN
INSERT INTO chat_bak(chat_id, msg)
VALUES(old.chat_id, old.msg);
END;
$$
데이터 삭제후에 백업하는 트리거 생성시
DELIMITER $$
CREATE TRIGGER chat_bak_tr
AFTER DELETE ON chat
FOR EACH ROW BEGIN
INSERT INTO chat_bak(chat_id, msg)
VALUES(new.chat_id, new.msg);
END;
$$
TRIGGER 목록 출력
SHOW TRIGGERS;
TRIGGER 사용
데이터 저장
SELECT * FROM chat;
INSERT INTO chat(msg)
VALUE ('hello database'), ('use workbench'), ('write query');
SELECT * FROM chat;
SELECT * FROM chat_bak;
데이터 삭제
DELETE FROM chat
WHERE chat_id IN(1, 3)
LIMIT 2;SELECT * FROM chat;
(잘못 삭제된) 데이터 복원
SELECT chat_id, msg FROM chat_bak;INSERT INTO chat(chat_id, msg)
SELECT chat_id, msg FROM chat_bak;
SELECT * FROM chat;
SELECT * FROM chat_bak;
복원한 후에도 bak_date 안에는 그대로 데이터가 있슴. 거기에는 유니크한 chat_id가 그대로 남아있기 때문에
추후 다시한번 삭제시 에러가 발생함.
그럼으로, 복원후에는 백업방에 있는 복원자료는 삭제해야 한다.
DELETE FROM chat_bak
WHERE chat_id IN(1, 3)
LIMIT 2;
SELECT * FROM chat_bak;
SELECT * FROM chat;상관계수, 회귀분석
- 기술통계 여러개의 숫자들을 하나의 숫자로 만들어 내는 것
평균(나누기)
분산(제곱)
표준편차(루트)
공분산 : 방향성 o, 강도 x
상관계수 : 방향성 o, 강도 o
결정계수 : 방향성 x, 강도 o, 상관관계^2
최적화되고, 효율적인 코드작성을 하려면 수학적 지식이 있어야 한다.
통계에 대한 내용도 알고 이해하면 훨씬 좋다.
회귀분석
대부분 수치형 데이터를 예측하기 위함
상관관계 실습1
SQL을 이용한 상관계수분석
income, rating 사이에 상관관계를 분석
가설 : 소득이 높으면 신용점수가 높다.
적용 : 소득으로 신용점수를 예측하는 데이터로 사용
USE quiz1;
SELECT income, rating FROM credit;
COV : 공분산 : 분자사용-----------------------계산이복잡함으로 소수점정리는 안함----------------
n : 데이터갯수 : 400
SELECT COUNT(*) FROM credit;
x_ : 소득평균 : 45.219
SELECT ROUND(AVG(income), 3) FROM credit;
y_ : 신용점수평균 : 354.940
SELECT ROUND(AVG(rating), 3) FROM credit;
COV : n, x_, y_ : 4305
SELECT SUM((income - 45.219) * (rating - 354.940)) / 400
FROM credit;
ROOT(X분산 * Y분산) : 분모사용-----------------계산이복잡함으로 소수점정리는 안함---------------
X분산 : 1239.05
SELECT VARIANCE(income) FROM credit;
Y분산 : 23879.71
SELECT VARIANCE(rating) FROM credit;
ROOT(X분산 * Y분산) : 5440
SELECT
POW (
(SELECT VARIANCE(income) FROM credit)
* (SELECT VARIANCE(rating) FROM credit), 0.5) # 0.5의 제곱은 루트와 같음
AS var
FROM dual;
SELECT POW(9, 0.5);
상관계수 : 0.7914
분자 : 4305, 분모 : 5440
SELECT 4305 / 5440 FROM dual;
> 소득은 신용점수와 강한 양의 상관관계를 갖는다.
> 신용점수를 예측할때 소득 데이터를 사용하면 좋은 예측 성능을 발휘한다.
위 계산은 간편하게 하기 위해 숫자를 넣었지만,
실무에서는 서브쿼리로 계산한다. (서브쿼리 3단계정도 들어가 진다.)
상관관계 실습2
풀이1 -----------------------------------------쉽게풀기
USE quiz1;
SELECT * FROM kospi_usd;
DESC kospi_usd;
데이터타입 변경
ALTER TABLE kospi_usd MODIFY COLUMN tdate DATE;
DESC kospi_usd;
2020년도 ~ 2023년도 원달러환율, 코스피주가 데이터
원달러환율(x), 코스피지수(y) 상관관계 출력
데이터갯수(n)
SELECT * FROM kospi_usd;
COV : 공분산 : 분자사용
n : 데이터갯수 : 985
SELECT COUNT(*) FROM kospi_usd;
x_ : 원달러환율 : 1229
SELECT ROUND(AVG(usd)) FROM kospi_usd;
y_ : 코스피지수평균 : 2588
SELECT ROUND(AVG(kospi)) FROM kospi_usd;
분자 : 공분산 (COV) : -15349
n:985, x_:1229, y_ :2588
SELECT SUM((usd - 1229) * (kospi - 2588)) / 985
FROM kospi_usd;
ROOT(X분산 * Y분산) : 분모사용-----------------계산이복잡함으로 소수점정리는 안함---------------
X분산 : 7088
SELECT ROUND(VARIANCE(usd)) FROM kospi_usd;
Y분산 : 139259
SELECT ROUND(VARIANCE(kospi)) FROM kospi_usd;
ROOT(X분산 * Y분산) : 31417
SELECT
POW (
(SELECT VARIANCE(usd) FROM kospi_usd)
* (SELECT VARIANCE(kospi) FROM kospi_usd)
, 0.5) AS var # 0.5의 제곱은 루트와 같음
FROM dual;
풀이2 -----------------------------------------서브쿼리로풀기
SELECT
(SELECT
SUM((usd - (SELECT ROUND(AVG(usd)) FROM kospi_usd))
* (kospi - (SELECT ROUND(AVG(kospi)) FROM kospi_usd)))
/ (SELECT COUNT(*) FROM kospi_usd)
FROM kospi_usd
)
/
(SELECT
POW(
(SELECT VARIANCE(usd) FROM kospi_usd)
* (SELECT VARIANCE(kospi) FROM kospi_usd)
, 0.5)
FROM dual
)
FROM dual;

상관계수 : -15349 / 31417 : -0.4886
분자 : 7088, 분모 : 139259
SELECT -15349 / 31417 FROM dual;
> 환율과 코스피 상관관계는 0.4886으로 의미 있는 상관관계를 갖는다.
> 하지만 아주 강한 상관관계는 아니다.
'데이터 분석 (DA)' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 12주차 (DA_Tableau) (0) | 2025.03.09 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 8주차 (DA_MySQL) (0) | 2025.02.06 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 4주차 (DA_Python) (0) | 2025.01.12 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 3주차 (DA_Python) (0) | 2025.01.04 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 2주차 (DA_Statistics) (2) | 2024.12.29 |



