Database
1. DB (Database)
- 데이터를 통합하여 관리하는 데이터 집합
2. DBMS (Database Management System)
- 데이터베이스를 관리하는 관리시스템 또는 프로그램
2-1. DBMS 종류
2-1-1. RDBMS (Relational Database Management System)
- 데이터 테이블 사이에 관계를 가지는 데이터 베이스 (Oracle, MySQL, Postgresql, Sqlite)
2-1-2. NoSQL (Not Only SQL)
- 데이터 테이블 사이에 관계를 갖지 않는 데이터베이스 (Mongodb, Hbase, Cassandra)
 |
|
|
|
|
|
|
2-2. DBMS 특징
2-2-1. RDBMS
- 데이터 분류, 정렬, 탐색속도가 빠름.
- CRUD (Create Read Update Delete)
- Read가 빠름
- 오래 사용되서 신뢰가 높음
- 구조의 수정이 어려움
2-2-2. NoSQL
- 데이터의 저장, 수정, 삭제, 확장이 빠름
- CRUD (Create Read Update Delete)
- Create, Update, Delect가 빠름
- Collection 사이에 관계를 가질 수 없슴
- 데이터 저장이 유연함
2-3. Schema
- 데이터베이스 구조에 대한 디자인
2-4. SQL Query
- 데이터베이스 서버에서 데이터를 가져오기 위한 문법
SQL 분류
1. DML (Data Manupulation Language)
- 데이터 조작어 (SELECT, INSERT, UPDATE, DELETE)
1-1. DML - CREATE
1-2. DML - READ
1-3. DML - UPDATE
1-4. DML - DELETE
2. DDL (Data Definition Language)
- 데이터 정의어 (CREATE, ALTER, DROP, RENAME, TRUNCATE)
2-1. DDL - CREATE
2-2. DDL - READ
2-3. DDL - UPDATE
2-4. DDL - DELETE
3. DCL (Data Control Language)
- 데이터 제어어 (GRANT, REVOKE)
4. TCL (Transaction Control Language)
- 트랜잭션 제어어 (COMMIT, ROLLBACK, SAVEPOINT)
5. DML 설명
5-1. DML - CREATE
INSERT INTO <table_name> (<column>)
VALUES (<value1>, <value2>), (<value3>, <value4>)
5-2. DML - READ
SELECT <column>
FROM <table_name>
WHERE : BETWEEN, IN, NOT IN, LIKE
ORDER BY : ASC, DESC
LIMIT
GROUP BY <column_name>
HAVING <condition>
JOIN <table_name>
ON <condition>
5-3. DML - UPDATE
UPDATE <table_name>
SET <column_name> = <value>
WHERE
LIMIT
5-4. DML - DELETE
DELETE FROM <table_name>
WHERE
LIMIT
6. DDL 설명
6-1. DDL - CREATE
CREATE DATABASE <database_name>
CREATE TABLE <table_name>
6-2. DDL - READ
SHOW DATABASES
SHOW TABLES
DESC <table_name> # Schima보기
6-3. DDL - UPDATE
ALTER DATABASE <database_name> CHARACTER SET = <encoding_name>
ALTER TABLE <table_name> ADD <column_name> <datatype>
ALTER TABLE <table_name> MODIFY COLUMN <column_name>
ALTER TABLE <table_name> DROP <column_name>
6-4. DDL - DELECT
DROP DATABASE <database_name>
DROP TABLE <table_name>
TRUNCATE <table_name>
MySQL
- 오픈소스이며 다중 사용자와 다중 스레드 지원
- 표준 SQL 사용
- 세계적으로 가장 많이 사용하는 데이터베이스
- 라이센스
- MySQL을 포함하는 하드웨어나 소프트웨어 기타장비를 판매하는 경우 라이센스 필요
- 서비스에 이용하는것은 무료
MySQL Query
1. SQL 쿼리 종류
1-1. DML : 데이터 조작어 : 데이터 CRUD : 트랜잭션 사용(O)
- C(INSERT INT0) R(SELECT FROM) U(UPDATE SET) D(DELETE FROM)
1-2. DDL : 데이터 정의어 : 데이터베이스, 테이블 CRUD : 트랜잭션 사용(X)
- C(CREATE) R(SHOW, DESC) U(ALTER) D(DROP)
1-3. DCL : 데이터 제어어 : 시스템 CRUD
2. DML : READ : SELECT FROM
- SELECT <columns> FROM <table_name>
3. 명령어
- * (별) : 모든
- country 테이블로부터 모든 컬럼을 가져오겠다.
- 코딩 컨벤션(스타일) : 명령어는 대문자로 작성한다.
- ; (세미콜론) : SQL쿼리(명령어)의 마지막을 의미한다.
- - comment : 주석
- -- : 한줄주석
- /* 여러줄주석 */ : 여러줄주석
SELECT *
FROM world.country;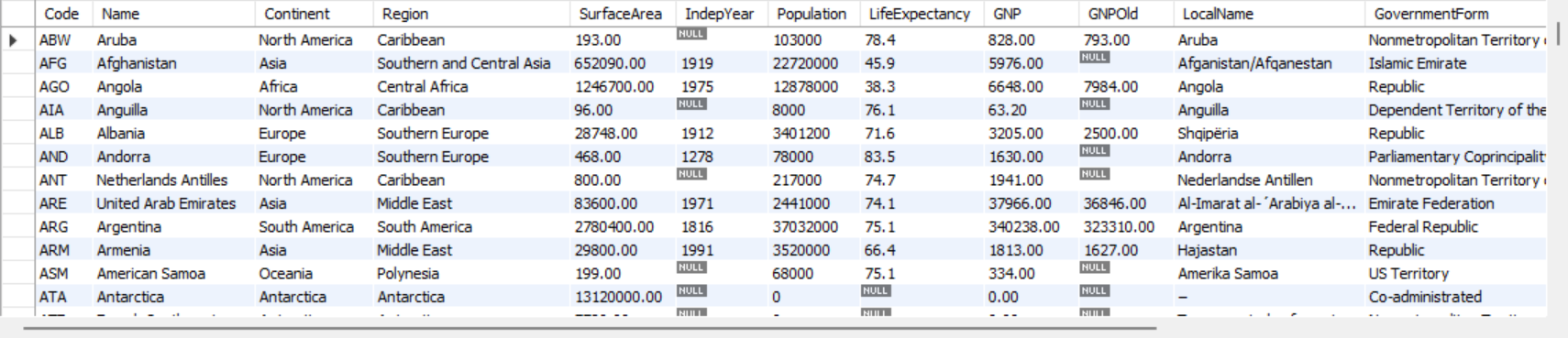
데이터베이스 선택
USE world;
선택된 데이터베이스 확인
SELECT database();
sakila 데이터베이스선택 > 선택된 데이터베이스 확인 (출력)
USE sakila;
SELECT database();
SELECT *
FROM world.city; # world 데이터베이스 city 출력
SELECT *
FROM city; # sakila 데이터베이스 city 출력
데이터베이스 이름없이 world 데이터베이스의 city 테이블 데이터 출력
USE world;
SELECT *
FROM city;
국가코드, 국가이름, 대륙이름, 인구수 출력
SELECT code, name, continent, population -- 컬럼이름은 대소문자를 구분(X)
FROM country;
AS : alias : 컬럼이름을 변경하여 출력할때 사용
SELECT code AS country_code, name, continent, population
FROM country;
sakila 데이터베이스에 있는 film 테이블의 모든 데이터 출력
USE sakila;
영화제목, 영화설명, 상영시간, 등급데이터 출력
SELECT title AS film_title, description, length, rating
FROM film;
csv파일로 저장하기 : 탑메뉴에서 Query > EXPORT RESULT > 저장
DDL : READ
데이터베이스 목록 출력
SHOW DATABASES;
테이블 목록 출력
USE world;
SHOW TABLES;
테이블 스키마 출력
DESC city;
DML : READ : SELECT FROM
SELECT FROM : 특정 테이블에 있는 특정 컬럼을 출력
WHERE : 특정 조건을 설정하여 조건에 맞는 ROW 데이터 출력
조건설정 : 연산자(Operator)사용 : 산술, 비교, 논리alter
연산자
산술연산자 : 데이터 + 데이터 = 데이터 : +, - < *, /, % (컬럼과 컬럼값을 연산할때도 많이 쓰임)
비교연산자 : 데이터 + 데이터 = 논리값 (참(1), 거짓(0)) 불리형 : =, !=, >, <, >=, <=
논리연산자 : 논리값(비교(연산)결과) + 논리값(비교(연산)결과) = 논리값 : NOT, AND(True AND True = True, 나머지는 False), OR(False OR False = False, 나머지는 True) : 조건 2개 이상
산술연산자
SELECT, WHERE 구문에서 사용 가능
컬럼추가 : 인구밀도 (인구수 / 국가면적)
SELECT code, name, continent, surfacearea, population
, population / surfacearea AS pps
FROM country;
국가코드, 국가이름, 인구수, GNP 출력
컬럼추가 : 1인당 GNP (단위 : *10000)
SELECT code, name, population, gnp, round(gnp / population * 10000, 2) AS gpp
-- round함수 : 소수점 두자리까지 반올림 적용함 -- 1인당 gnp (gpp) : gnp per person
FROM country;
csv파일 복원하기 (Titanic파일 복원하기)
bda 데이터베이스 생성 : DDL CREATE
CREATE DATABASE bda;
SHOW DATABASES;
이후에 스키마 테이블에서 오른쪽클릭 > Table Data Import Wizard 클릭
DROP DATABASE bda; -- 에러날 경우 데이터베이스 다시 만든후 테이블값 입혀라
CREATE DATABASE bda;
SHOW DATABASES;
비교연산자 : 데이터 + 데이터 = 논리값 : 조건 1개
논리연산자 : 논리값 + 논리값 = 논리값 : 조건 2개 이상
계좌잔고(balance), 인출금액(amount)
계좌잔고에서 인출금액을 인출할 수 있으면 True, 없으면 False 출력
조건1 : 계좌잔고가 인출금액보다 많거나 같으면 인출 가능
balance >= amount
조건2 : 1회 최대 인출 금액은 5000원 이다.
amount <= 5000
인출이 가능하려면, 조건1과 조건2를 모두 만족 (두 조건 모두 True 일때 True 출력) (T AND T = T)
(balance >= amount) AND (amount <= 5000)
T AND T = T, T AND F = F, F AND T = F, F AND F = F
USE world;
컬럼추가 : 아시아 대륙이면 1을 출력 : True(1), False(0)
컬럼추가 : 인구수가 1000만명 이상이면 1 출력 : upper_1000 -- 1000 * 10000 으로 표기하면 가독성이 좋아진다.
컬럼추가 : 아시아 대륙중에 인구수가 1000만명 이상이면 1 출력 : is_asia_1000
SELECT code, name, continent, population
, continent = 'Asia' AS is_asia
, population >= 1000 * 10000 AS upper_1000
, (continent = 'Asia') AND (population >= 1000 * 10000) AS is_asia_1000
FROM country;
# WHERE : 특정 조건에 데이터를 필터링하여 출력
SELECT code, name, continent, population
FROM country
WHERE (continent = 'Asia') AND (population >= 1000 * 10000);
괄호를 사용하는 이유 : 코드의 가독성을 좋게 하기 위해서 : 사용하지 않아도 동일한 결과가 나오기는 하지만 복잡해지면 실수하기 쉬움 : 공동작업시 혼란생김
연산자 우선순위 : 1.산술연산자 > 2.비교연산자 > 3.논리연산자
SELECT code, name, continent, population
FROM country
WHERE continent = 'Asia' AND population >= 1000 * 10000;
쿼리의 실행 순서 : FROM > WHERE > SELECT 그럼으로 아래와 같이 쿼리 실행시 에러가 나옴.....is_asia를 찾을 수 없슴......
SELECT code, name, continent, population
, continent = 'Asia' AS is_asia
FROM country
WHERE is_asia = 1;
# 결과 : 에러
country 테이블에서 아시아와 아프리카 대륙의 국가 데이터 출력
출력컬럼 : code, name, continent, population
조건1 : 아시아 대륙국가 : continent = 'Asia'
조건2 : 아프리카 대륙국가 : continent = 'Africa'
SELECT code, name, continent, population
FROM country
WHERE (continent = 'Asia') OR (continent = 'Africa');
기타연산자 IN 사용시
SELECT code, name, continent, population
FROM country
WHERE continent IN('Asia', 'Africa');
# city 테이블에서 한국(countrycode = 'KOR')에 있는 도시중에 인구수 100만 이상인 도시를 출력
# 출력컬럼 : countrycode, name, population
# 조건1 : 한국도시 : countrycode = 'KOR'
# 조건2 : 인구수 100만명이상 : population >= 100 * 10000
SELECT *
FROM city;
SELECT countrycode, name, population
FROM city
WHERE (countrycode = 'KOR') AND (population >= 100*10000);
코딩 스타일(컨벤션)
파이썬 : PEP8 -- PEP8 code Guide 문서가 코드 스타일 가이드이며 꼭 지켜서 해야함.
DATABASE(명령어, 상수선언)
data_base(snake_case:컬럼이름, 함수, 변수식별자)
DataBase(PascalCase:클래스식별자, 클래스선언)
dataBase(camelCase:자바스크립트(변수선언))
코드작성 : 문법(잘못쓰면 에러발생), 컨벤션(잘못쓰면 보기안좋음) ★
두줄_표현시-1
SELECT code, name, population
, gnp / population
FROM country;
두줄_표현시-2
SELECT code, name, population,
gnp / population
FROM country;
===>> 두줄_표현시_1번이 더 좋다. 쉼표를 윗줄에 붙이면 혹시 두번째줄 조건 삭제시 윗줄 쉼표로 인해 에러발생 할 수 있으며, 조건 수정시 두줄을 해야하는 번거로움이 있슴으로 표현-1과 같이 하는 것을 추천한다.
(첫 수업 정리)
데이터베이스 구조
데이터베이스 서버 > 데이터베이스(관계X) > 테이블(관계O) > 로우
SQL Query : 데이터베이스에서 데이터를 CRUD하기 위한 명령(코드)
SQL 종류 : DML(데이터), DDL(데이터베이스, 테이블), DCL(시스템)
DML READ : SELECT <columns> FROM <table_name> WHERE <condition>
조건작성 : 연산자 : 산술, 비교(조건1개), 논리(조건2개이상)
논리연산자 : AND(모든조건만족), OR(하나의 조건만 만족)
연산자 우선순위 : 산술 > 비교 > 논리
쿼리 실행 순서 : FROM > WHERE > SELECT
(복습)
SQL 종류
DML : 데이터 : CRUD
- C(INSERT INTO)R(SELECT FROM)U(UPDATE SET)D(DELECT FROM)
DDL : 데이터베이스, 테이블 : CRUD
- C(CREAT)R(SHOW,DESC)U(ALTER)D(DROP)
DCL : 시스템
TCL : 트랜젝션
DML : READ
SELECT <column> AS(alias:컬럼이름변경할때)
FROM <table_name>
WHERE <condition>
condition 작성 : Operator(연산자)
- 산술연산자 : 데이터 + 데이터 = 데이터 : +, - < *, /, %
- 비교연산자 : 데이터 + 데이터 = 논리값 : =, !=, >, <, >=, <=
- 논리연산자 : 논리값 + 논리값 = 논리값 : NOT, AND(T:둘다 만족할때 출력), OR(F:둘중 하나를 만족할때 출력) : 조건 2개 이상 일때 사용
- 연산자 우선순위 : 산술 > 비교 > 논리 : 우선순위가 있더라도 가독성 위해 괄호를 써준다.
구문 우선순위 : FROM > WHERE > SELECT > ORDER BY > LIMIT
world 밑에 titanic 테이블 만들기
world 밑에 titanic 테이블 만들기-1
Table Data import wizard > csv 파일 선택 > ok > ok > ... > finish
FLUSH TABLES; 에러날 경우 FLUSH TABLES 해주면 된다. 클라이언트컴과 데이터컴의 트랜젝션이 잘 안될경우임. 그럼으로 메모리에 있던 세션을 다시 시작해준다.
world 밑에 titanic 테이블 만들기-2
file > open SQL Script > titanic.sql 해서 번개표시 실행하면 world 밑에 테이블 생성됨.
USE world;
SELECT *
FROM titanic;
(연습문제)
생존여부, 좌석등급, 나이, 요금, 승선위치데이터 출력하기
출력컬럼 : survived, pclass, age, fare, embarked
SELECT survived, pclass, age, fare, embarked
FROM world.titanic;
(연습문제)
컬럼추가 : 나이데이터를 연령대 데이터로 연산하여 ages 컬럼을 추가
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic;
(연습문제)
조건1 : 30대~40대 연령대를 갖는 승객 데이터 필터링 하여 출력
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
WHERE (age >= 30) AND (age <= 49);
# FROM 다음 WHERE이 실행됨으로 ages로 분석하면 에러남. 그럼으로 age를 분석해야함.
-- BETWEEN AND : 특정 범위내 데이터를 선택할때 사용
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
WHERE age BETWEEN 30 AND 49;
(연습문제)
조건1 : 승선위치가 C, Q인 데이터를 필터링하여 출력
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
WHERE (age BETWEEN 30 AND 49) AND ((embarked = "C") OR (embarked = "Q"));
IN, NOT IN : 특정 컬럼에 특정 데이터 포함 여부에 따라 데이터 출력
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
WHERE (age BETWEEN 30 AND 49) AND (embarked IN ("C", "Q"));
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
WHERE (age BETWEEN 30 AND 49) AND (embarked NOT IN ("C", "Q"));
# NOT IN 사용시 "C", "Q"이외의 값이 있는 로우를 출력함.
LIKE : 특정 문자열이 포함된 데이터 출력
% 의미 : 아무문자 0개 이상
영화설명에 robot이 들어간 영화 목록 출력
USE sakila;
SELECT title, description, length
FROM film
WHERE description LIKE "%robot%";
USE world;
국가코드에 K가 들어가는 국가 데이터 출력
SELECT code, name
FROM country
WHERE code LIKE "%K%";
국가코드가 K로 시작하는 국가 데이터 출력
SELECT code, name
FROM country
WHERE code LIKE "K%";
WHERE 구문에서 사용 가능한 명령어
- BETWEEN AND, IN, NOT IN, LIKE
ORDER BY : 데이터 정렬하여 출력
ASC(오름차순:생략가능), DESC(내림차순)
(연습문제)
조건1 : 도시의 인구수가 많은 순으로 정렬하여 출력
SELECT countrycode, population, name
FROM city
ORDER BY population DESC;
(연습문제)
조건1 : 국가코드를 알파벳 순으로 정렬하여 출력
SELECT countrycode, population, name
FROM city
ORDER BY countrycode DESC;
SELECT countrycode, population, name
FROM city
ORDER BY countrycode;
컬럼 여러개를 지정해서 정렬 가능
우선순위는 왼쪽에서 오른쪽으로.
/(연습문제)
조건1 : 국가코드를 내림차순으로 정렬한 후
조건2 : 국가코드의 우선순위가 같으면 인구수 오름차순으로 정렬
SELECT countrycode, population, name
FROM city
ORDER BY countrycode DESC, population ASC;
쿼리 실행 순서 : FROM > WHERE > SELECT > ORDER BY
- 내가만든 컬럼에 대한 검색은 ORDER BY에서는 사용이 가능하다......
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
ORDER BY ages ASC;
(연습문제)
조건1 : 성인승객 20세 이상
조건2 : 성인승객 중에서 연령대가 낮은 순으로 정렬하고, 연령대가 같으면 요금이 높은 순으로 정렬하고, 요금도 같으면 나이역순으로 출력
SELECT survived, pclass, age, fare, embarked
, (age - age % 10) AS ages
FROM titanic
WHERE age >= 20 -- 조건1
ORDER BY ages ASC, fare DESC, age DESC; -- 조건2
(연습문제)
LIMIT : 데이터 갯수 제한
국가의 인구수가 많은 상위 5개 국가 데이터 출력
출력컬럼 : 국가코드, 국가이름, 국가인구수, 대륙이름
인구수 내림차순 정렬 > 상위 5개 데이터 제한하여 출력
SELECT code, name, population, continent
FROM country
ORDER BY population DESC
LIMIT 5;
LIMIT 설명
LIMIT num1 : num1 (limit)
LIMIT num1, num2 : num1(skip), num2(limit)
-- 인구수가 많은 3위 ~ 5위 데이터 출력
SELECT code, name, population, continent
FROM country
ORDER BY population DESC
LIMIT 2, 3;
( tip )
-- 웹페이지에서 페이지 블럭을 설정할 수 있다....
page = 3, page_block = 20
LIMIT (page - 1) * page_block, page_block;
(복습)
DML : READ
SELECT : column : AS : 산술
FROM : table name
WHERE : condition : Operator (산술,비교,논리)
- BETWEEN AND, IN, NOT IN, LIKE
ORDER BY : ASC, DESC
LIMIT : num1(limit) : num1(skip),num2(limit)
=== 데이터베이스 생성 ===
DDL : CREATE
DROP DATABASE IF EXISTS bda;
CREATE DATABASE bda;
SHOW DATABASES;
USE bda;
=== 테이블 생성 ===
컬럼이름, 데이터타입, 제약조건
USE world;
DESC city; -- DESC : 테이블의 스키마 보여주기
=== 데이터 타입 ===
- (물리적) 저장공간을 효율적으로 사용하기 위해서 설정해 줌
- 데이터 찾기 위한 시간도 줄울 수 있슴 (최적화로 인해 작업 속도도 높일 수 있슴)
- 숫자, 문자열, 날짜
number : INT, FLOAT,
String : CHAR, VARCHAR, TEXT
Date : DATETIME(직접입력), DATESTAMP(현재날짜)
=== 제약조건 ===
- NOT NULL : 결측 데이터 X
- UNIQUE : 중복 데이터 X
- PRIMARY KEY : ROW 데이터 구별 : NOT NULL + UNIQUE
- DEFAULT : 데이터가 저장하려는 데이터가 없을때 저장되는 데이터 설정
각 타입형 설명
- 기술서적 : 서점 서적 90%가 입문서임. 그럼으로 고성능 자료 이용시 사이트에 있는 Document / User Guide 찾아보면 된다.
1. 숫자형 데이터타입 (Number)
- TINYINT (1Bytes) (정수형) (나이값에 적당 0~256, -128~0~127)
- INT (4Bytes) (정수형)
- BIGINT (8Bytes) (정수형)
- FLOAT (실수형)
- DOUBLE (실수형)
2. 문자열 데이터타입 (String)
- CHAR : 고정 길이 문자열 (국가코드에 적합)
- VARCHAR : 가변 길이 문자열 (국가명에 적합)(댓글데이터)
- TEXT : 긴문자 (기사내용)
3. 날짜형 데이터타입 (Date)
- DATETIME (직접입력)
- DATESTAMP (현재날짜)
=== 테이블 생성 : 컬럼명, 데이터타입, 제약조건 ===
- rdate : 등록날짜 의미임
USE bda;
CREATE TABLE user(
user_id INT PRIMARY KEY AUTO_INCREMENT
, name VARCHAR(20) NOT NULL
, email VARCHAR(30) UNIQUE NOT NULL
, age INT DEFAULT 30
, rdate TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
DESC user;
=== 데이터 생성 ===
- DML : CREATE : INSERT INTO
SELECT * FROM user;
- 한번에 한 로우의 데이터 입력하기
INSERT INTO user(name, email, age)
VALUE ('andy', 'andy@gmail.com', 26);
SELECT * FROM user;
- 한번에 많은 로우의 데이터 입력하기
INSERT INTO user(name, email, age)
VALUE ('alice', 'alice@naver.com', 34)
, ('peter', 'peter@naver.com', 24)
, ('jhon', 'jhon@naver.com', 39);
SELECT * FROM user;
- 나이 입력 안했지만 default값인 30이 들어가졌슴
INSERT INTO user(name, email)
VALUE ('anchel', 'anchel@gmail.com');
SELECT * FROM user;
- 이메일이 중복되어 Duplicate entry 에러가 남.
INSERT INTO user(name, email)
VALUE ('anchel2', 'anchel@gmail.com');
SELECT * FROM user;
- user_id 순번표기가 건넌 뛴 이유는 위에서 이메일때문에 에러가 났어도
- AUTO_INCREMENT는 자동으로 계속 실행되고 있기 때문이다.
INSERT INTO user(name, email)
VALUE ('jason', 'jason@gmail.com');
SELECT * FROM user;
쿼리를 실행한 결과를 INSERT 하기
1. KOR 확인하기
USE world;
SELECT countrycode, name, population
FROM city
WHERE countrycode = 'KOR';
2. 작성된 출력 결과물을 kor_city에 저장하기위해 테이블 만들기
DROP TABLE IF EXISTS kor_city;
CREATE TABLE kor_city(
countrycode CHAR(3)
, name VARCHAR(20)
, population INT
);
DESC kor_city;
3. 작성된 출력 결과물을 kor_city에 저장하기
INSERT INTO kor_city
SELECT countrycode, name, population
FROM city
WHERE countrycode = 'KOR';
SELECT * FROM kor_city;
DML 데이터내 정보 수정/업데이트 하기
- DML UPDATE : UPDATE SET
USE bda;
SELECT * FROM user;
UPDATE user
SET age = 40
WHERE name LIKE 'a%'
LIMIT 2;
SELECT * FROM user;
DML 데이터내 정보 삭제하기
DML DELETE : DELETE FROM
WHERE LIMIT
DELETE FROM user
WHERE name LIKE 'a%'
LIMIT 2;
SELECT * FROM user;
DDL 데이터내 정보 수정하기
DDL UPDATE : ALTER
데이터베이스 인코딩 방식 수정
현재 데이터베이스 인코딩 확인
SHOW VARIABLES LIKE 'character_set_database';
ALTER DATABASE bda CHARACTER SET = ascii;
인코딩을 다시 되돌릴 때
ALTER DATABASE bda CHARACTER SET = utf8mb4;
SHOW VARIABLES LIKE 'character_set_database';
DESC user;
테이블 컬럼 추가
DDL UPDATE
ALTER TABLE user ADD contents TEXT;
DESC user;
# ALTER TABLE user ADD contents TEXT DEFAULT 'no data'; # 다른 제약조건도 더 사용 가능함....
테이블 컬럼 타입 수정
ALTER TABLE user MODIFY COLUMN contents VARCHAR(200);
DESC user;
테이블 컬럼 삭제
ALTER TABLE user DROP contents;
DESC user;
DDL 테이블 삭제
DDL DELECT : DROP
DROP TABLE user;
DESC user;
DDL 데이터베이스 삭제
DROP DATABASE bda;
(복습)
DML : DATA
- C(INSERT INTO VALUES)R(SELECT FROM)U(UPDATE SET)D(DELETE FROM)
DDL : DATABASE, TABLE
- C(CREATE)R(SHOW, DESC)U(ALTER)D(DROP)
Tip...
업데이트나 딜리트는 원본정보 수정되는 것이므로, 아주 중요함.
현재 실행되고 있는 SQL 목록
SHOW PROCESSLIST;
-- 실행중인 쿼리의 강제 실행중단
KILL 11;
탑메뉴 > Database > Revers Engineer : 데이터베이스를 EER 다이어그램으로 출력
EER 다이어그램으로 데이터베이스와 테이블 생성
(두번째 수업 정리)
DDL :CRUD
CREATE TABLE
- 컬럼이름, 데이터타입, 제약조건
- 데이터타입
- 숫자(INT, FLOAT, DOUBLE), 문자(CHAR, VARCHAR), 날짜(DATETIME, TIMESTAMP)
- 제약조건 : NOT NULL, UNIQUE, PRIMARY KEY, DEFAULT, FOREIGN KEY
DML CREATE : INSERT INTO
DML UPDATE : UPDATE SET : WHERE, LIMIT 반드시 사용
DML DELETE : DELETE FROM : WHERE, LIMIT 반드시 사용
DDL UPDATE : TABLE ADD, MODIFY COLUMN, DROP : 컬럼 추가, 수정, 삭제
DDL DELETE : DROP
데이터베이스 모델링 : 개념적 모델링 > 논리적 모델링 > 물리적 모델링
(복습하기)
SQL 종류
DML : DATA : C(INSERT INTO)R(SELECT FROM)U(UPDATE SET)D(DELECT FROM)
DDL : DATABASE TABLE : C(CREATE)R(SHOW,DESC)U(ALTER)D(DROP)
DCL : 시스템
TCL : 트랜잭션
DQL : SELECT FROM
DML READ
SELECT columns : AS
FROM : table name
WHERE : condition
- Operator : 산술, 비교(조건1개), 논리(조건2개이상:NOT, AND(T), OR(F))
- 연산자 우선순위 : 산술 > 비교 > 논리
ORDER BY : ASC, DESC
LIMIT : num1(limit) : num1(skip) num2(limit)
구문 우선순위 : FROM > WHERE > SELECT > ORDER BY > LIMIT
DDL CREATE
데이터베이스, 테이블 생성
테이블 생성 : 컬럼이름(영어로), 데이터타입, 제약조건
데이터 타입
- 숫자(INT,FLOAT,DOUBLE), 문자(CHAR(글자수고정),VARCHAR(글자수가변적),TEXT)
, 날짜(DATETIME(직접입력),TIMESTAMP(현재시간기록))
제약조건
- NOT NULL, UNIQUE, PRIMARY KEY(로우데이터구분기능포함) (클러스터형 인덱스가 자동 생성되어 이 키를
기준으로 정렬됨_데이터를 좀더 빨리찾을수 있도록 한다.)
, DEFAULT, AUTO_INCREMENT, CURRENT_TIMESTAMP
- FOREIGN KEY (외래키)
DDL UPDATE, DELETE
UPDATE(ALTER) : 데이터 추가(ADD), 수정(MODIFY COLUMN), 삭제(DROP)
DELETE(DROP)
DML CREATE : INSERT INTO <table_name>(columns) VALUES (values or SELECT구문)...
DML UPDATE : UPDATE <table_name> SET <column=value> WHERE LIMIT
DML DELETE : DELETE FROM <table_name> WHERE LIMITE
데이터베이스 모델링
EER 다이어그램 : Datebase > Reverse Engineer, Foward Engineer
모델링 순서 : 개념적모델링 > 논리적모델링 > 물리적모델링
WHERE 구문에서 사용가능한 명령어
BETWEEN AND, IN, NOT IN, LIKE(%:퍼센트의 의미)
테이블 정보 확인하기
USE world;
SELECT * FROM country;
SELECT *
FROM country
WHERE indepyear IS NOT NULL;
NULL 데이터 처리 : IS NULL, IS NOT NULL
!= NULL; 사용불가
데이터분석 프로세스
문제정의 > 데이터수집 > 데이터처리 > 데이터분석 > 결론도출
데이터 처리 : 불필요한 컬럼제거 > 결측 데이터 처리(제거, 채움) > 명목형데이터를 수치형데이터로 변환
외래키 : FOREIGN KEY
참조를 당하는 컬럼은 UNIQUE, PRIMARY KEY 제약조건이 설정되어야 가능
데이터의 무결성(원하지 않는 데이터가 저장되지 않음)을 지켜줌
CREATE DATABASE fkbda;
USE fkbda;
1. user 테이블 생성
CREATE TABLE user(
ui INT PRIMARY KEY AUTO_INCREMENT
, name VARCHAR(20)
);
DESC user;
2. money 테이블 생성
CREATE TABLE money(
mi INT PRIMARY KEY AUTO_INCREMENT
, income INT NOT NULL
, ui INT
);
DESC money;
3. user 테이블 데이터 추가
INSERT INTO user(name)
VALUES ('A'), ('B'), ('C');
SELECT * FROM user;
# user 테이블에 데이터 추가할때 잘못해서 두번 눌렀을 때 잘못된 자료 삭제 하는 법
DELETE FROM user WHERE ui > 3 LIMIT 10;# user 테이블에 중복되어 있어서 잘 안되는 경우 기존 테이블 삭제하기
DROP table user;
4. money 테이블 데이터 추가
INSERT INTO money(income, ui)
VALUE (1000, 1), (2000, 3);
SELECT * FROM money;
INSERT INTO money(income, ui)
VALUE (3000, 4);
SELECT * FROM money;
FOREIGN KEY로 연결하기....
5. money 테이블 생성으로 다시가서....
DROP TABLE money;
CREATE TABLE money(
mi INT PRIMARY KEY AUTO_INCREMENT
, income INT NOT NULL
, ui INT
, FOREIGN KEY (ui) REFERENCES user(ui)
);
DESC money;
SELECT * FROM user;
SELECT * FROM money;

# 6. money 테이블 데이터 추가
INSERT INTO money(income, ui)
VALUE (1000, 1), (2000, 3);
SELECT * FROM money;
INSERT INTO money(income, ui)
VALUE (3000, 4);
SELECT * FROM money;
# 여기서 에러가 발생함 = FOREIGN KEY로 인해 로우가 고정되어 있기 때문에 더이상 값이 들어가지 않음...
7. user 테이블 데이터 삭제 (ui = 3)
DELETE FROM user
WHERE ui = 3
LIMIT 1;
# 여기서 에러가 발생함 = FOREIGN KEY로 인해 ui=3이 다른 테이블과도 연결되어있기 때문에 삭제 될 수 없슴...
SELECT * FROM money;

DESC user;
DESC money;

8. EER로 확인하기
- Datebase > Reverse Engineer
외래키 설정
- CASCADE : 데이터 동기화
- SET NULL : 데이터 NULL
- NO ACTION : 아무런 행동하지 않음 (거의 안씀)
- SET DEFAULT : 데이터 DEFALULT값으로 변경
- RESTRICT : 에러 발생
9. money 테이블 재생성
DROP TABLE money;
CREATE TABLE money(
mi INT PRIMARY KEY AUTO_INCREMENT
, income INT NOT NULL
, ui INT
, FOREIGN KEY (ui) REFERENCES user(ui)
# 업데이터 될 때는 동기화, 삭제할 때는 NULL 데이터로 변경
ON UPDATE CASCADE ON DELETE SET NULL
);
DESC money;
SELECT * FROM money;

10. money 테이블 데이터 추가
INSERT INTO money(income, ui)
VALUE (1000, 1), (2000, 3);
SELECT * FROM money;
SELECT * FROM user;
user테이블 UPDATE하기 (부모테이블에서 바꿔야함. 그래야 자식테이블도 바뀜. 반대로는 바뀌어지지 않음)
UPDATE user
SET ui = 4
WHERE ui = 3
LIMIT 1;
SELECT * FROM user;
SELECT * FROM money;
#프로필 바꾸면 타임라인 컨텐츠들 모두 바뀌는 것과 같은 원리임.

user 테이블 DELETE
DELETE FROM user
WHERE ui = 1
LIMIT 1;
SELECT * FROM user;
SELECT * FROM money;
# user 아이디 삭제되면서 money테이블에 있던 ui 값은 NULL 됨.
# 그래서 9번에 있는 DELETE SET NULL를 실행해 주는 것임...

(함수 학습)
함수 : 미리 만들어 놓은 특별한 기능
단일행함수 : 함수가 1개의 데이터 적용 (단일 로우 마다 적용됨)
- 올림, 내림, 버림, 합침, 날짜포맷변경
- CEIL(), ROUND(), TRANCATE(), CONCAT(), DATE_FORMAT()
다중행함수 : 함수가 1개의 컬럼에 적용 (전체값을 하나의 값으로 반환됨)
- 샘, 합, 평균, 최저, 최고, 분산
- COUNT(), SUM(), AVG(), MIN(), MAX(), VARIANCE()
CEIL() : 올림 : 자리수 설정 불가 / 자리수 설정 위해서는 연산자 이용해서 수동으로 해야함
SELECT CEIL(12.345), (12.345 * 100) / 100
FROM dual;
# dual은 테이블이 아닌 그냥 한줄의 행을 출력해주는 가상의 테이블임.
ROUND() : 반올림 : 자리수 설정 가능함
자리수 설정하지 않으면 소수 첫번째에서 반올림 > 정수형태로 출력
SELECT ROUND(12.345, 2), ROUND(12.345), ROUND(12.345, 0), ROUND(1351, -2)
FROM dual;
TRUNCATE() : 버림 : 자리수를 반드시 설정해야 함
SELECT TRUNCATE(12.345, 2), TRUNCATE(12.345, 0), TRUNCATE(1351, -2)
FROM dual;
USE world;
SELECT code, name, population, surfacearea
, ROUND(population / surfacearea, 2) AS pps
FROM country;
컬럼추가 : 나이를 연령대로 변경하여 ages 컬럼 추가 (함수사용)
SELECT survived, age, fare, embarked
, TRUNCATE(age, -1) AS ages
FROM titanic;
DATE_FORMAT() : 날짜 데이터의 포맷 변경 (KPI 지표에 많이 사용함)
예) : 년월일 시분초 > 년월 : > 요일
USE sakila;
SELECT payment_date, amount
FROM payment;
SELECT payment_date
, DATE_FORMAT(payment_date, '%Y-%m') AS monthly1
, DATE_FORMAT(payment_date, '%Y-%M') AS monthly2
, amount
FROM payment;
SELECT payment_date
, DATE_FORMAT(payment_date, '%W') AS weekly1
, DATE_FORMAT(payment_date, '%w') AS weekly2
, amount
FROM payment;
CONCAT() : 컬럼의 데이터를 결합하여 출력
USE world;
SELECT * FROM country;
국가이름(국가코드) 출력하는 컬럼추가
SELECT name, code, CONCAT(name, "(", code, ")") AS name_code
FROM country;
다중행함수 : 함수가 1개의 컬럼에 적용 (전체값을 하나의 값으로 반환됨)
COUNT() : ROW 데이터의 갯수 출력
SELECT COUNT(*)
FROM country;
SELECT COUNT(code)
FROM country;
SELECT COUNT(population)
FROM country;
# COUNT(<column_name>)의 경우 결측치값 빼고 출력된다.
아시아 대륙의 국가수를 출력
SELECT COUNT(*)
FROM country
WHERE continent = 'Asia';
country 테이블에서 code 컬럼과, indepyear 컬럼의 결측 데이터가 아닌 데이터수 출력
1개의 ROW로 출력
SELECT COUNT(indepyear)
FROM country;
두가지 개수를 표현할때 (subSELECT 개념임)
SELECT
(SELECT COUNT(code) FROM country) AS code
, (SELECT COUNT(indepyear) FROM country) AS indepyear
FROM dual;
SUM() : 모든 데이터를 더해주는 함수
조건1 : 아시아 대륙의 총인구수 출력
조건2 : 아시아 대륙의 평균인구수 출력
SELECT continent, SUM(population), ROUND(AVG(population))
FROM country
WHERE continent = "Asia";
# 에러나는 경우 예시
SELECT code, SUM(population)
FROM country
WHERE continent = "Asia";
MIN() : 최소값 출력
MAX() : 최대값 출력
조건1 : 한국의 도시중에서 인구수가 가장 많은 도시의 인구수와 가장 적은 인구수 출력
조건2 : 한국 도시에서 인구수가 가장 많은 도시 대비 가장 적은 도시의 인구수 비율 출력
SELECT countrycode, MAX(population), MIN(population)
, round((MIN(population) / MAX(population)) * 100, 2)
FROM city
WHERE countrycode = "KOR";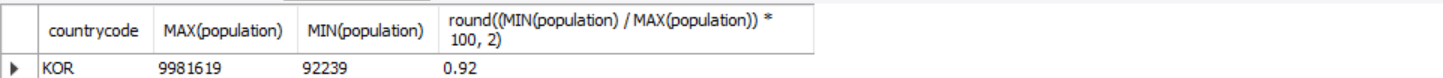
DISTINCT() : 중복 데이터 제거하여 출력
전세계 대륙목록 출력
SELECT DISTINCT(continent)
FROM country;
SELECT DISTINCT(continent) AS con
FROM country
ORDER BY con ASC;
# 순서가 섞여서 출력되는 이유는 눈에 보이지는 않지만 공백 또는 특수문자등이 섞여있기 때문이다...
(연습문제)
조건1 : 매출이 발생한 년월 데이터 목록을 출력
SELECT DISTINCT(DATE_FORMAT(payment_date, '%Y-%m')) AS sdate
FROM payment
ORDER BY sdate DESC;
에러 사유 찾기
1. 일단 데이터포맷 적용함. 이경우에는 문제없슴.
SELECT payment_date, DATE_FORMAT(payment_date, '%Y-%m') AS sdate
FROM payment;
2. 이경우에는 에러 발생함....왜냐하면 출력값 payment_date ROW행 갯수와 DISTINCT의 ROW행 갯수가 맞지 않기 때문이다.
SELECT payment_date, DISTINCT(DATE_FORMAT(payment_date, '%Y-%m')) AS sdate
FROM payment;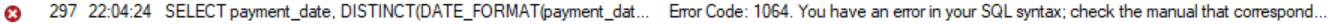
USE world;
SELECT 'city_name' AS category,
(SELECT name
FROM city
WHERE conturycode = 'KOR'
ORDER BY population ASC
LIMIT 1) AS min_name
, (SELECT name
FROM city
WHERE countrycode = 'KOR'
ORDER BY population DESC
LIMIT 1) AS max_name
FROM dual
UNION
SELECT 'population', MIN(population), MAX(population)
FROM city
WHERE countrycode = "KOR";
-----------------------------------------------------
조건문 : 특정 조건에 따라서 다른 결과를 출력하는 방법
조건 1개 : IF(condition, true date, false data)
인구수 100만 이상이면 big, 아니면 small을 출력하는 scale컬럼 추가
USE world;
SELECT countrycode, name, population
, IF(population >= 100 * 10000, 'big', 'small') AS scale
FROM city;
조건 2개 : CASE WHEN THEN ELSE END
인구수 100만 이상이면 bign 10만~100만이면 medium, 10만 이하이면 small 출력
SELECT countrycode, name, population
, CASE
WHEN <condition> THEN <data>
WHEN <condition> THEN <data>
ELSE
END AS scale
FROM city;
SELECT countrycode, name, population
, CASE
WHEN population >= 100 * 10000 THEN 'big'
# WHEN population >= 10 * 10000 AND (population < 100 * 10000) THEN 'medium'
# (population < 100 * 10000)이 필요없는 경우 : 파이썬과 같이
# 첫칸에서 'True'를 통과했슴으로 밑에서는 중복할 필요 없다.
WHEN (population >= 10 * 10000) THEN 'medium'
ELSE 'small'
END AS scale
FROM city;
BETWEEN AND 사용도 가능하지만 잘 사용하지는 않는다.
SELECT countrycode, name, population
, CASE
WHEN population >= 100 * 10000 THEN 'big'
WHEN population BETWEEN 10 * 10000 AND 100*10000-1 THEN 'medium'
ELSE 'small'
END AS scale
FROM city;
-----------------------------------------------------
IFNULL : 결측 데이터를 채워주는 용도로 사용되는 함수
indepyear 컬럼에서 결측 데이터를 0으로 채워서 출력
SELECT code, name, indepyear, IFNULL(indepyear, 0)
FROM country;
SELECT COUNT(indepyear)
FROM country;
indepyear 컬럼에서 결측 데이터를 평균값으로 채워서 출력
SELECT code, name, indepyear
, IFNULL(indepyear, (SELECT AVG(indepyear) FROM country))
FROM country;
GROUP BY : 같은 데이터를 그룹핑하여 결과 출력하는 문법
특정컬럼(중복결합), 다른컬럼(결합함수결합)
조건1 : 대륙별 총 인구수와 총 국가수를 출력
조건2 : continent(중복결합), population(결합함수결합) : SUM(), COUNT()
조건3 : 인구수가 1만명 미만인 국가는 포함하지 않는다.
조건4 :총인구수가 많은 1위~3위까지의 대륙 목록 출력
USE world;
SELECT code, continent, SUM(population) AS sum_pop, COUNT(population) AS count_pop
# code와 결합함수간에 row데이터 개수가 틀림으로 에러남.
FROM country
GROUP BY continent;
조건1, 조건2 적용
SELECT continent, SUM(population) AS sum_pop, COUNT(population) AS count_pop
FROM country
GROUP BY continent;
조건3 적용
SELECT continent, SUM(population) AS sum_pop, COUNT(population) AS count_pop
FROM country
WHERE population >= 10000
GROUP BY continent;
조건4 적용
SELECT continent, SUM(population) AS total_pop, COUNT(population) AS count_pop
FROM country
WHERE population >= 10000
GROUP BY continent
ORDER BY total_pop DESC
LIMIT 3;
여러개의 컬럼 중복 결합
여러개의 컬럼의 데이터가 모두 같은 데이터끼리 중복 결합
대륙과 지역별 총 인구수 출력
특정컬럼 : continent, region
다른컬럼 : SUM(population)
SELECT continent, region, SUM(population)
FROM country
GROUP BY continent, region
ORDER BY continent;
TRIM 사용시
SELECT TRIM(continent) AS tcon, region, SUM(population)
FROM country
GROUP BY continent, region
ORDER BY tcon;
WITH ROLLUP : 그룹별 총합을 출력하는 ROW 추가하는 명령어
SELECT TRIM(continent) AS tcon, region, SUM(population)
FROM country
GROUP BY continent, region
WITH ROLLUP;
SELECT TRIM(continent) AS tcon
, IFNULL(region, 'total')
, SUM(population)
FROM country
GROUP BY continent, region
WITH ROLLUP;
(예제) 연령대별 생존자수 출력
SELECT age, TRUNCATE(age, -1) AS ages, survived
FROM titanic;
SELECT TRUNCATE(age, -1) AS ages, SUM(survived)
FROM titanic
GROUP BY ages
ORDER BY ages;
(예제) 연령대별 생존자수 출력 + 생존률(srate) 출력하는 컬럼 추가
SELECT TRUNCATE(age, -1) AS ages, SUM(survived)
, ROUND( SUM(survived) / COUNT(*) * 100 ,2) AS srate
FROM titanic
GROUP BY ages
ORDER BY ages;
# 어린 아이들 생존율이 높았다. 이는 성인들이 어린아이들을 살리기 위해 많이 희생했다.
(예제) 연령(age)대별 성(sex)별 생존자수 출력 + 생존률(srate) 출력하는 컬럼 추가
SELECT TRUNCATE(age, -1) AS ages
, sex
, SUM(survived)
, ROUND( SUM(survived) / COUNT(*) * 100 ,2) AS srate
FROM titanic
GROUP BY ages, sex
ORDER BY ages;
(복습)
함수
단일행 : CEIL, ROUNT, TRUNCATE, CONCAT, DATE_FORMAT, DISTINCT
다중행 : SUM, COUNT, MIN, MAX, AVG, ...
조건문
조건 1개 : IF(condition, true, false)
조건 2개 이상 : CASE WHEN THEN ELSE END
결측 데이터 처리 : INNULL (column, data)
그룹핑
GROUP BY : 특정컬럼(중복결합), 다른컬럼(결합함수결합)
WHIS ROLLUP : 그룹별 통계치를 출력할 때 사용
'데이터 분석 (DA)' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 12주차 (DA_Tableau) (0) | 2025.03.09 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 9주차 (DA_MySQL) (0) | 2025.02.14 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 4주차 (DA_Python) (0) | 2025.01.12 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 3주차 (DA_Python) (0) | 2025.01.04 |
| [패스트캠퍼스] 데이터 분석 부트캠프 17기 - 2주차 (DA_Statistics) (2) | 2024.12.29 |



